久方ぶりの更新です。
例え更新がなかろうと、広告が出ないのが「GitHub Pages」のいいところですよね。
さて、前回の記事で改善点の中に、
”合成音声生成器 (new)” と書いていたことを覚えている方はいるでしょうか。
今回は、タイトルの通り、佐奈の音声をdeeplearningして、
合成音声を作るための前説明です。
自分の理解を整理する意味でも書いているので、しばしお付き合いください。
ぶっちゃけ、ネットに転がっている情報以上のことは何もない。
分かった気にはなれると……思う。
音声合成とは
音声合成(おんせいごうせい、英: speech synthesis)とは、
人間の音声を人工的に作り出すことである。
音声情報処理の一分野。
音声合成器により合成された音声を合成音声(ごうせいおんせい)と呼ぶ。
典型的にはテキスト(文章)を音声に変換できることから、
しばしばテキスト音声合成またはText-To-Speech (TTS)とも呼ばれる。
なお、歌声を合成するものは特に歌声合成と呼ばれる。
また、音声を別の個人あるいはキャラクターの音声に変換する手法は声質変換と呼ばれる。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
つまり、佐奈の声を誰でも作り出すことができる技術なのだ!
Wikiの通り、大きく2通りの方法がある。
①テキスト音声合成
②声質変換
本件は①について取り上げていく。
②については、こちらの方の動画が分かりやすいです。(丸投げ)
Vtuberになって、自分で美声出したい!とかであれば声質変換でもいいかもしれませんね。
ちなみに、歌声合成はこちらの方の動画が素敵です。(丸投げ2回目)
これは、初見で感動した……
NEUTRINOという歌声合成エンジンを使ってるそうです。
チューニングとか必要らしい。
詳しい①と②の比較:
美少女声への変換と合成
話を戻して、①のテキスト音声合成(以下、TTSと略します)についてお話します。
お馴染みなところで並べると、Softalkの「ゆっくりボイス」、VOCALOIDの「初音ミク」、VOICEROIDの「結月ゆかり」と、ニコニコ動画でよく見るやつ。
入力した文字列を音声として返す、それだけなんだが、作るとなるといろいろと難しい。
そこを機械的にやってしまおうというのが深層学習の意図でもあります。
ディープラーニングによるTTSについて

まずは、実際に聞いてみましょう。
合成音声サンプル
英語で何言ってるかは分からんですが、英語を流暢にしゃべっているということは分かった。
この例では、「Tacotron 2」、「WaveNet」という大きく二つのネットワークを用いている。
・Tacotron 2:テキストからメルスペクトログラム(mel-spectrogram)
・WaveNet:メルスペクトログラム(mel-spectrogram)から音声波形
上記の役割をそれぞれ持っており、結果、テキストから音声へ変換されている。
詳しい実装が知りたい人向け:https://google.github.io/tacotron/
さて、今回の実装では「WaveNet」を、
処理が軽量化するらしいNVIDIA製の「WaveGlow」に置き換えることにした。
準備編
サンプルがあるので、興味ある人は是非やってみて欲しい。
以下のページがとても参考になりました。
音声合成を試す1 Tacotron2 + WaveGlow
※パッケージのインストールは注意!(※””部分は必要)1
2
3
4
5
6
7
8
9
10
11
12%cd /content/tacotron2
!pip install matplotlib==3.0.0
!pip install tensorflow"==1.14.0"
!pip install inflect==0.2.5
!pip install librosa==0.6.0
"!pip install -U scipy"
!pip install tensorboardX==1.8
!pip install Unidecode==1.0.22
!pip install pillow
!pip install torch==1.0
!pip install torchvision==0.3.0
"!pip install -U numpy"
(2020/06/20時点)
これを使えば、いくらでも英語のリスニングテスト問題が生成できます。
あとは、ローカル環境に落とし込むだけ……!
Tacotron2 + WaveGlowについての参考:
Tacotron2を用いた日本語TTS(Text-to-Speech)の研究・開発【まとめ】
DeepLearningでアニメキャラのボイロを作った話
前処理編
参考ではイントネーションの付加情報などの工夫を見ますが、
まずはシンプルに佐奈のテキスト&音声のデータセットで学習させていきたいと思います。
(そもそも知ってから2週間も経ってない)
前提として、「WaveGlow」に関しては音声生成器なのでサンプルモデルを弄りません。
「Tacotron 2」の学習結果次第で変えていきたいと思います。
前例の方と実装はほぼ同じです。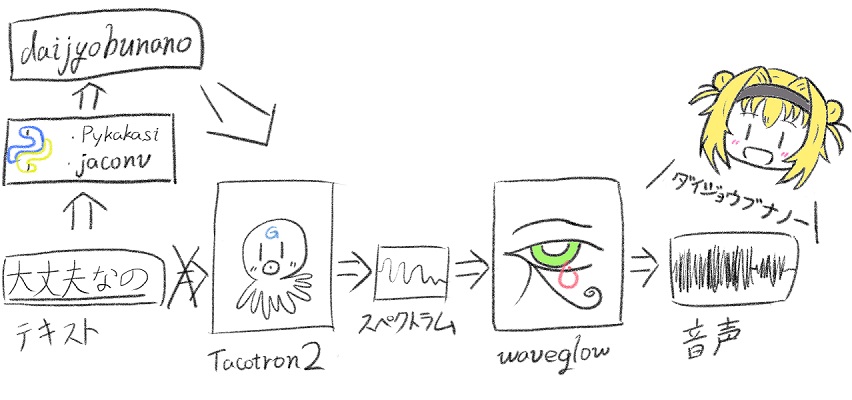
こんな感じ。
読み込む前に右へ倣えでローマ字変換、特殊文字の加工を施す。
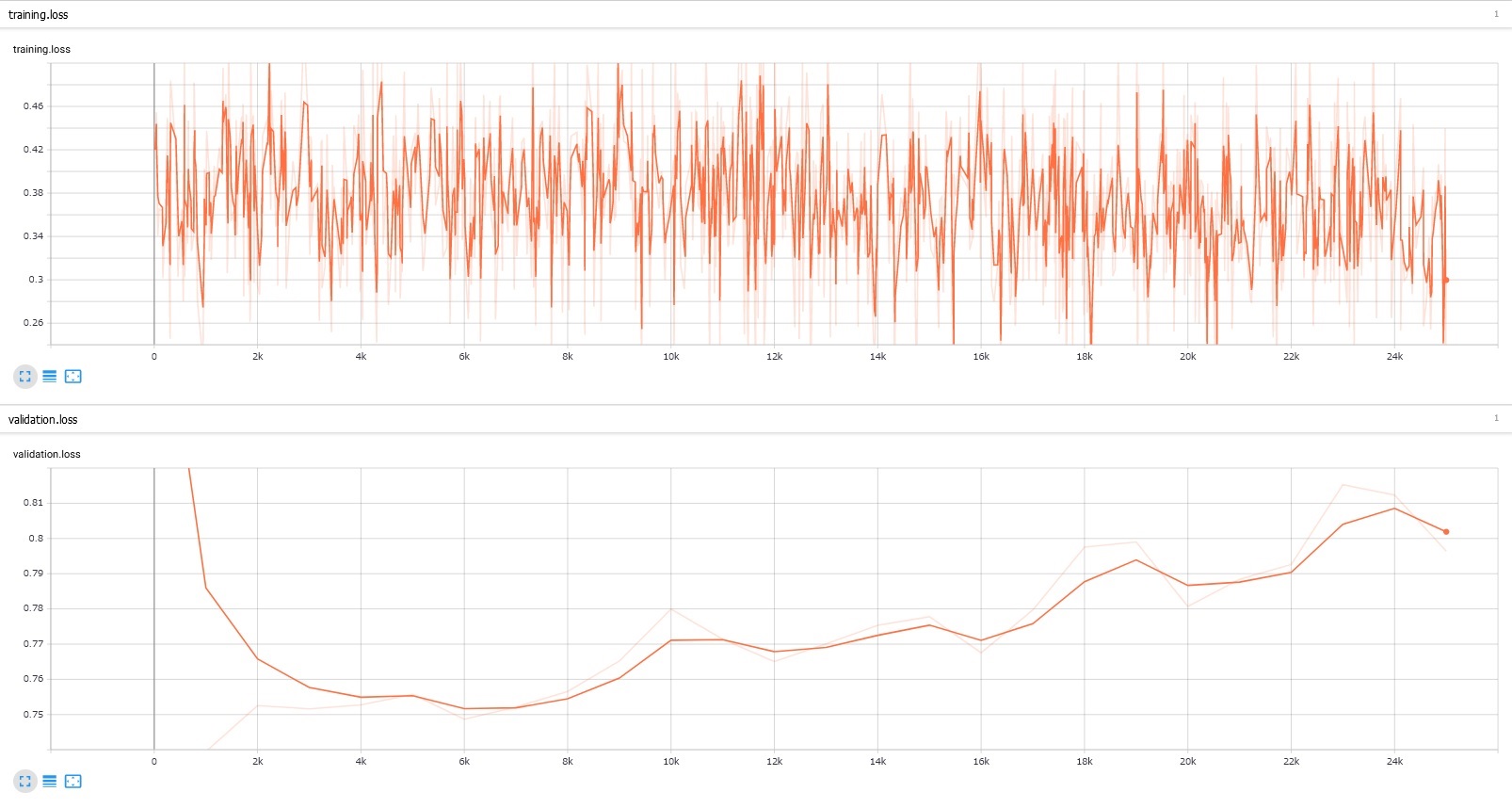
次回は学習結果を公開予定。
佐奈になるといいな~