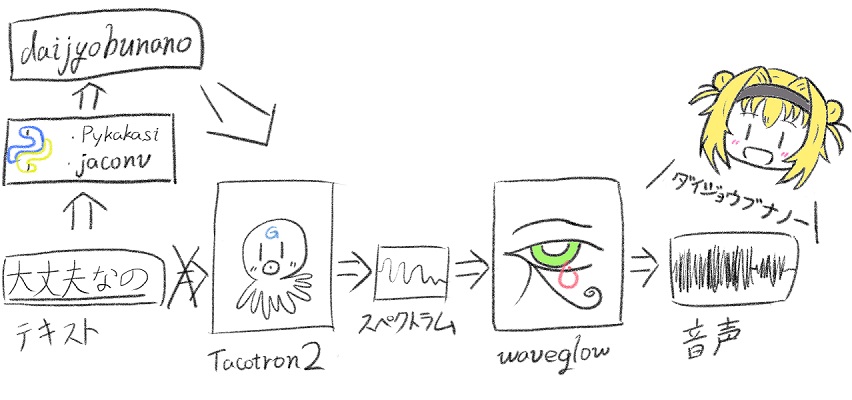
千歳佐奈のTTS、学習編①です。
用いたデータ数は、本編のセリフの約1000個で、主に佐奈√を除いたもの。
佐奈セリフの約1/3くらい。
文章成型については前記事通り、ローマ文字変換のみ、音声加工は無しで学習。
佐奈のお勉強が終わるまでトータル約51時間で丸2日とちょっとかかりました。※600000step
損失関数は以下の通り。
画像では60000~80000step以降佐奈の暴走(過学習)が起きています。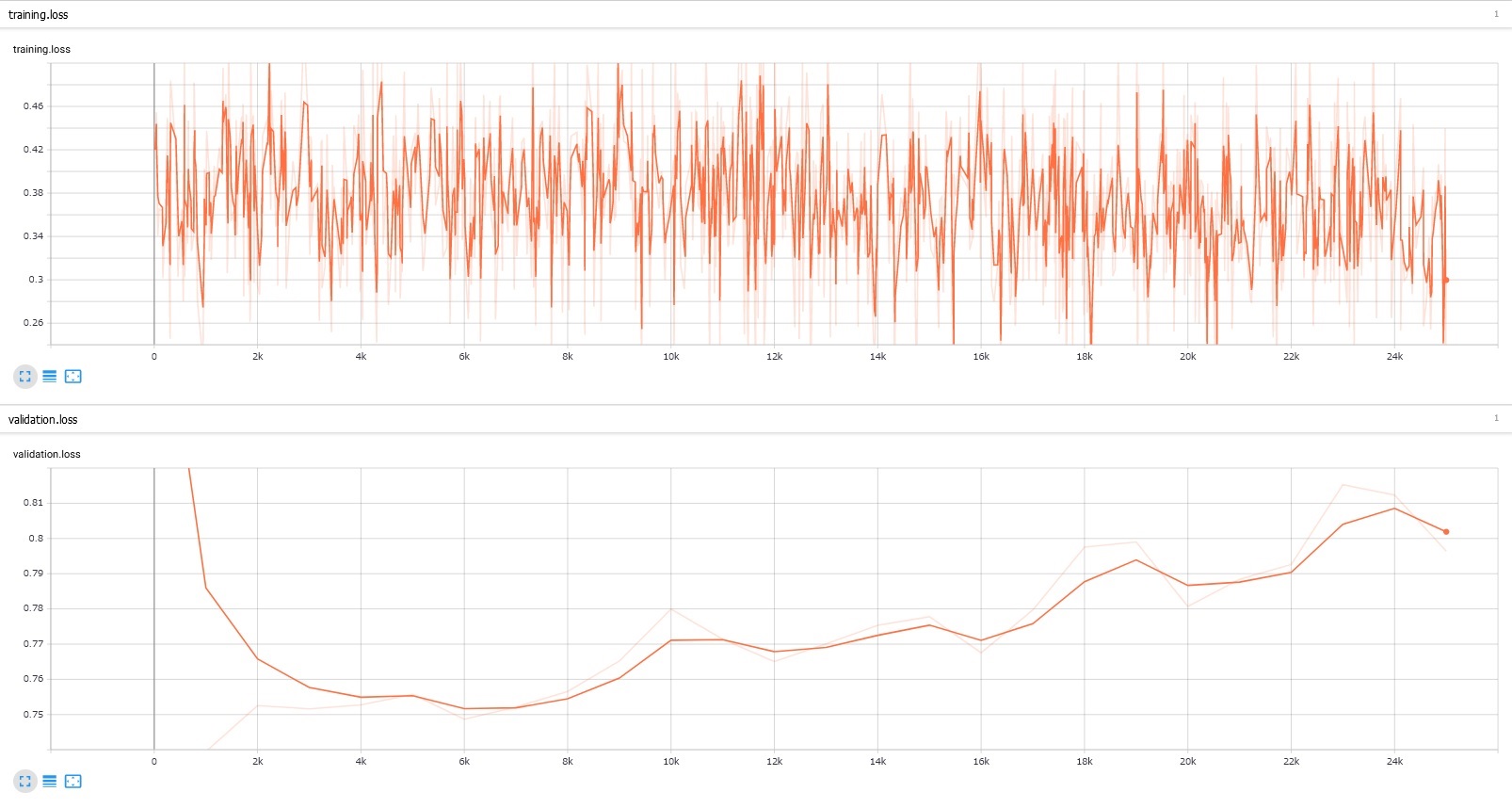
実際には60万stepで過学習が起きていますが、
エラー吐いて学習止まってることがあり、その度にグラフが0stepから始まっちゃいます。
綺麗につなぐ方法あったら教えてください( ;∀;)
佐奈のお勉強のテスト結果は以下の通り。
■成功例
・「おはようございます」
かわいい!大好き!
佐奈の定型文なだけあって、少しホッとした。
■失敗例
・「おはようございます、兄さん」
ぉはようございますススス…兄さん
ノイズが混じる~
・「兄さん、おはようございます」
ほへぇ…
最後の気になるけどかわいい~~~~~~!
・「大丈夫」
舌足らずでかわいい~~~~~!
・「大丈夫なの」
”な”が言えてない!おしい!
文章の前後入れ替えたり、ちょい足ししただけでもやっぱり結果が変わる。
ちなみにオリジナルのセリフもいくらか試してみたが、もはや言葉になってなかった……
成功例のも機械音混じりになってしまっているので、
これを良しとするかはなかなか決め兼ねるところです。
上記を踏まえて、今後の改善方針です。
改善点
①データ数
他記事などをみると言うほど少なくもないかもしれないが、
多いに越したことは無いので次回は増加して学習予定。
データ数は声質と比例関係にあると考える。
②文章の成型
音声と文章の突合についてはブラックボックスでやっているので、
セリフの”間”や長音、音声の無音部分については全く考慮していない。
特に佐奈は三点リーダを多用するので処理に困っている・・・・・・
オリジナルのセリフが弱いのはこちらが原因と考える。
データ増加後に検討予定。
③音声の成型
こちらも②同様。
ただし、文章を音声に寄せる方が遥かに楽そうなので、特に変更なし。
④WaveGlowモデル
音声の出力については、成功例にあるように佐奈の声質に近しいため、現状は変更なし。
機械音について気になるステージまで行ったら改良予定。
文章の成型について教えてください!!!